BTree和B+Tree
简介
B 树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树。(相对于二叉,B树每个内结点有多个分支,即多叉)
B树又可以写成B-树/B-Tree,并不是B“减”树,横杠为连接符,容易被误导
首先我们介绍一下一棵 m 阶B-tree的特性
m 阶的定义:一个节点能拥有的最大子节点数来表示这颗树的阶数
举个例子:
如果一个节点最多有 n 个key,那么这个节点最多就会有 n+1 个子节点,这棵树就叫做 n+1(m=n+1)阶树
包括以下5条特性
1.每个结点x(假设为x)有如下属性:
– x.n,表示当前存储在结点x中的关键字个数。
– x.n的各个关键字本身:x.key1, x.key2, … 以非降序存放(升序),使得 x.key1 ≤ x.key2 ≤ …
– x.leaf,是一个布尔值,如果x是叶子结点,则为TRUE, 如果x为内部结点,则为FALSE。2.每个’内部结点x’还包含x.n+1个指向它的孩子的指针x.c1, x.c2, … 。 叶子结点没有孩子结点,所以他的ci属性没有定义。
– key和指针互相间隔,节点两端是指针,所以节点中指针比key多一个。
– 每个指针要么为null,要么指向另外一个节点。3.关键字x.keyi对存储在各子树中的关键字进行分割:如果ki为任意一个存储在以x.ci为根的子树中的关键字,那么:
k1 ≤ x.key1 ≤ k2 x.key2 ≤ … ≤ x.keyx.n ≤ kx.n+1
难理解可以这么说:
> 如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于(key1),其中(key1)为node的第一个key的值。> 如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于(keym),其中(keym)为node的最后一个key的值。
> 如果某个指针在节点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向节点的所有key小于(keyi+1)且大于(keyi)。
4.每个叶子结点具有相同的深度,即树的高度h
5.每个结点所包含的的关键字个数有上界和下界。用一个被称作B树的最小度数的估计整数t(t ≥ 2)来表示这些界:
除了根结点以外的每个结点必须**至少**有t-1个关键字。因此,除了根节点以外的每个内部结点**至少**有t个孩子。(因为上面说了右x.n+1个指向它的孩子的指针)
如果树非空,根结点至少有一个关键字。
每个结点**最多**包含2t-1个关键字。因此,一个内部节点至多可有2t个孩子。当一个结点恰好有2t-1个关键字时,称该结点是满的(full)。
3阶B-tree示意图
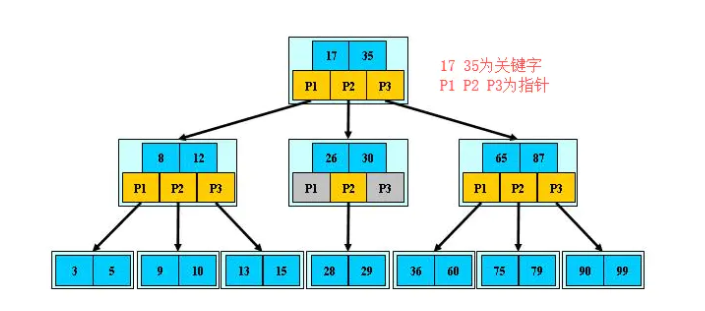
拿中间一层最左边举例说明:
1. x.n = 2 有俩个关键字
分别为 x.key1 = 8 x.key2 = 12 且 8<12
x.leaf = false为内部节点
2. 含有3个指向它孩子的指针P1 P2 P3
3. 关键字x.key1=8 它的左边指针P1 对 子树 3 5 分割 满足 3和5都小于8
关键字x.key1=8 它的右边指针P2 对 子树 9 10 分割 满足 9和10都大于8(同为12的左指针)
关键字x.key2=12 它的右边指针P3 对 子树 13 15 分割 满足 13和15都大于12
实际磁盘举例:
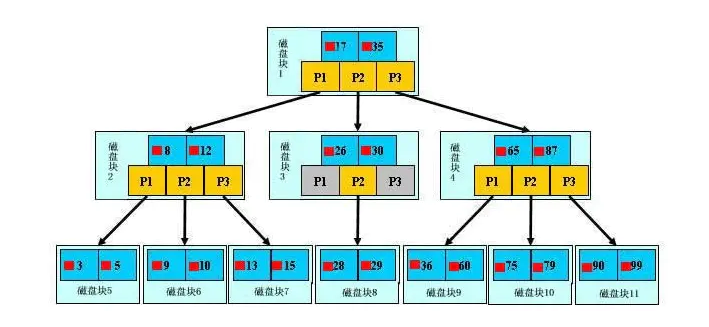
来模拟下查找
文件29的过程:(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。
【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。
【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。
【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
关键字插入操作
生成从空树开始,逐个插入关键字。但是由于B_树节点关键字必须大于等于[ceil(m/2)-1],(其中ceil(x)是一个取上限的函数)所以每次插入一个关键字;首先在最底层(叶子节点那一层)的某个非终端节点中添加一个“关键字”,该结点的关键字不超过m-1,则插入完成;否则要产生结点的“分裂”,将一半数量的关键字分裂到新的其相邻右结点中,中间关键字上移到父结点中。
下面一个实例:我们需要用C N G A H E K Q M F W L T Z D P R X Y S来构造5阶B树
这设计一个 B树的阶数的最优选取
- 首先,根结点空间足够,4个字母插入相同的结点中,如下图:
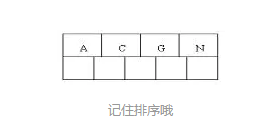
- 当咱们试着插入H时,结点发现空间不够,以致将其分裂成2个结点,移动中间关键字G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。如下图:
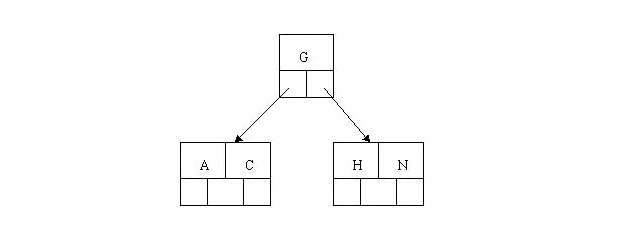
- 插入E,K,Q时,不需要任何分裂操作
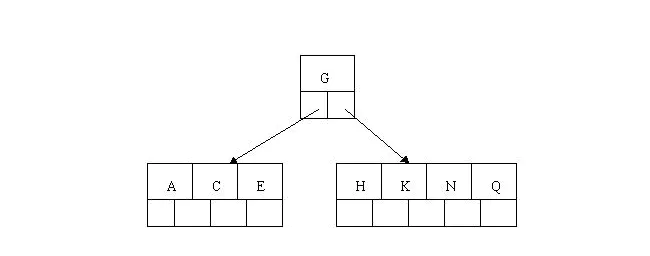
- 插入M需要一次分裂,注意M恰好是中间关键字,以致向上移到父节点中
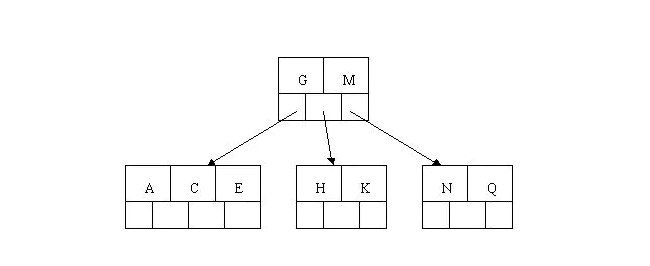
- 插入F,W,L,T不需要任何分裂操作
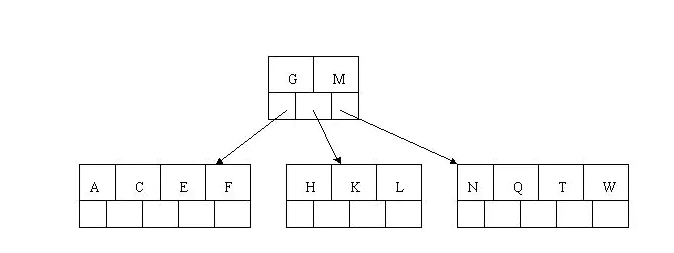
- 插入Z时,最右的叶子结点空间满了,需要进行分裂操作,中间关键字T上移到父节点中,注意通过上移中间关键字,树最终还是保持平衡,分裂结果的结点存在2个关键字。
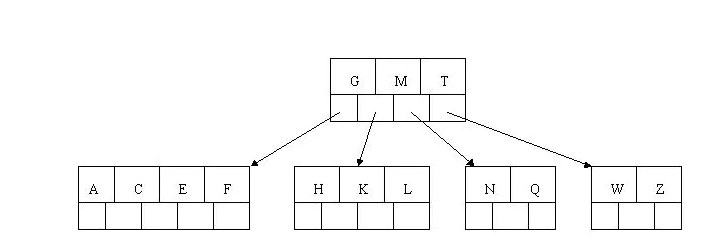
- 插入D时,导致最左边的叶子结点被分裂,D恰好也是中间关键字,上移到父节点中,然后字母P,R,X,Y陆续插入不需要任何分裂操作(别忘了,树中至多5个孩子)。
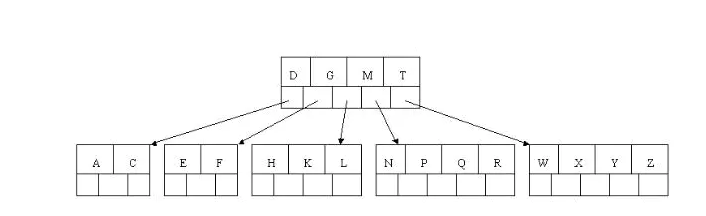
- 最后,当插入S时,含有N,P,Q,R的结点需要分裂,把中间关键字Q上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间关键字M上移到新形成的根结点中,注意以前在父节点中的第三个指针在修改后包括D和G节点中。这样具体插入操作的完成
关键字删除操作
首先查找B树中需删除的关键字,如果该关键字在B树中存在,则将该关键字在其结点中进行删除,如果删除该关键字后,首先判断其结点是否有左右孩子结点,如果有,则上移孩子结点中的某相近关键字到父节点中,然后是判断移动之后的情况;如果没有,直接删除后,判断删除之后的情况。
删除元素,移动相近元素之后,如果某结点中关键字数小于ceil(m/2)-1,
(m为阶数)则需要看其某相邻兄弟结点是否丰满
如果丰满,则向父节点借一个元素来满足条件;如果其相邻兄弟都刚脱贫,即借了之后其结点数目小于ceil(m/2)-1则该结点与其相邻的某一兄弟结点进行“合并”成一个结点,以此来满足条件。
(结点中关键字个数大于ceil(m/2)-1除根结点之外的结点的关键字的个数n必须满足:ceil(m / 2)-1)<= n <= m-1。m表示最多含有m个孩子,n表示关键字数.)
实例:
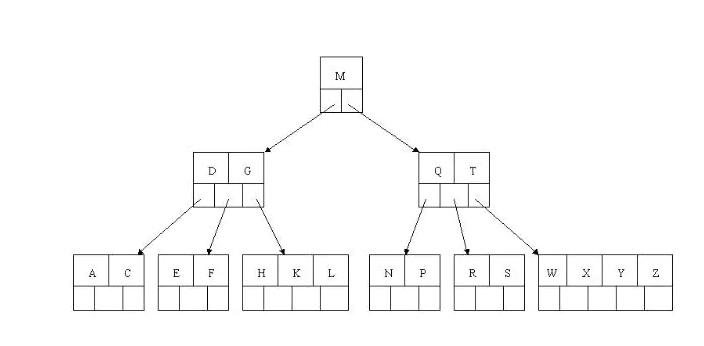
最初态5阶B树 实现依次删除H,T,R,E
关键字数最小为ceil(m / 2)-1=2。最多为m-1=4
- 首先删除关键字H,当然首先查找H,H在一个叶子结点中,且该叶子结点关键字数目3大于最小元关键字数目2,则操作很简单,咱们只需要移动K至原来H的位置,移动L至K的位置(也就是结点中删除关键字后面的关键字向前移动)
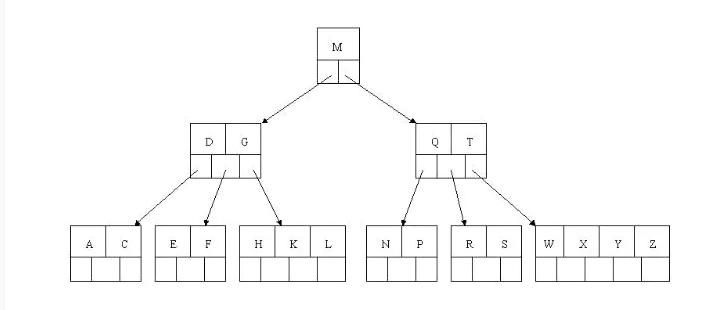
- 下一步,删除T,因为T在中间结点中,它有孩子,且关键字数目=2,所以需要向孩子借一个关键字W(一般借升序的下个关键字),将W上移到T的位置,然后将原包含W的孩子结点中的W进行删除,这里恰好删除W后,该孩子结点中关键字数目大于2,无需进行合并操作。
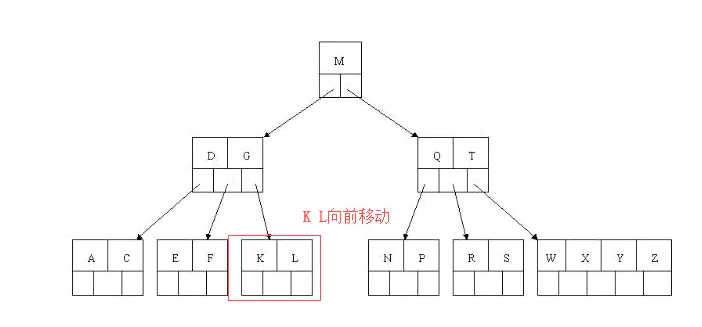
- 下一步删除R,R在叶子结点中,但是该结点中关键字数目为2,删除导致只有1个关键字,已经小于最小关键字数目
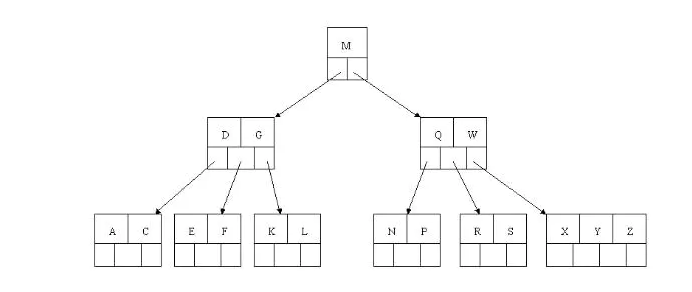
ceil(5/2)-1=2,而由前面我们已经知道:如果其某个相邻兄弟结点中比较丰满(关键字个数大于ceil(5/2)-1=2),则可以向父结点借一个关键字,然后将最丰满的相邻兄弟结点中上移最后或最前一个关键字到父节点中(有没有看到[红黑树]中左旋操作的影子?),在这个实例中,右相邻兄弟结点中比较丰满(3个关键字大于2),所以先向父节点借一个关键字W下移到该叶子结点中,代替原来S的位置,S前移;然后X在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除X,后面关键字前移。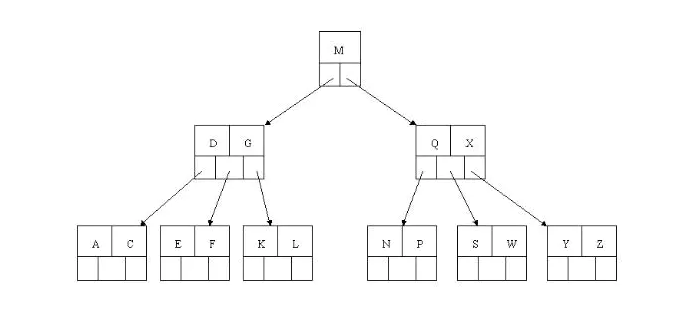
- 最后一步删除E, 删除后会导致很多问题,因为E所在的结点数目刚好达标,刚好满足最小关键字个数
(ceil(5/2)-1=2),而相邻的兄弟结点也是同样的情况,删除一个关键字都不能满足条件,所以需要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的关键字(该关键字在两个需要合并的两个结点关键字之间)下移到其子结点中,然后将这两个结点进行合并成一个结点。所以在该实例中,咱们首先将父节点中的关键字D下移到已经删除E而只有F的结点中,然后将含有D和F的结点和含有A,C的相邻兄弟结点进行合并成一个结点。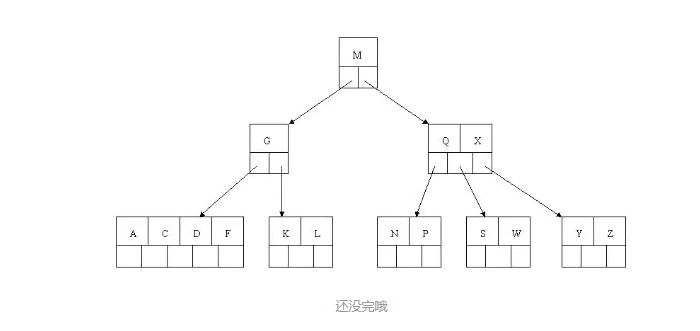 还没完哦
还没完哦 - 也许你认为这样删除操作已经结束了,其实不然,在看看上图,对于这种特殊情况,你立即会发现父节点只包含一个关键字G,没达标
(因为非根节点包括叶子结点的关键字数n必须满足于2=<n<=4,而此处的n=1)这是不能够接受的。
如果这个问题结点的相邻兄弟比较丰满,则可以向父结点借一个关键字。然后父亲再向孩子借一个关键字。但是它的兄弟也很贫穷。所以这时只能与兄弟结点进行合并成一个结点,而根结点中的唯一关键字M下移到子结点,这样,树的高度减少一层。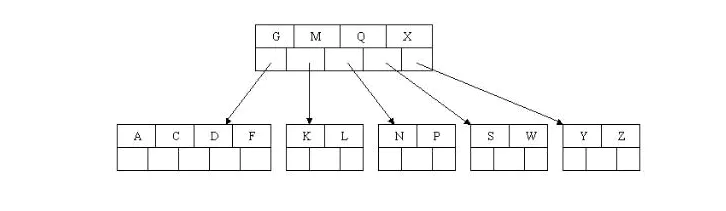
至此完成删除操作。
补充一下最后一个关键字删除的另外一种情况:也是5阶B树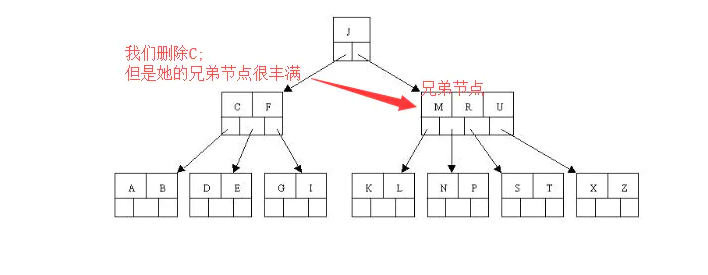
- 删除关键字C后发现只剩下一个关键字F所以我们打算去借,这个借首先想到孩子,然后再说父亲删除关键字C后D关键字上移到C的位置,但是出现上移关键字D后,只有一个关键字E的结点的情况。且它相邻兄弟结点才刚脱贫(最少关键字个数为2),不可能向父节点借关键字,所以只能进行合并操作,合并操作就要向父结点借一个元素,所以又把D借下来。于是这里将含有A,B的左兄弟结点,加上D关键字和含有E的结点进行合并成一个结点。
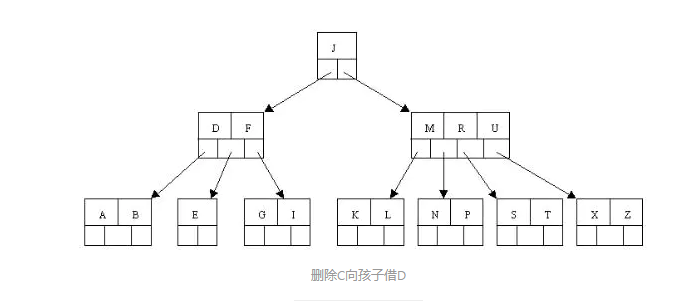
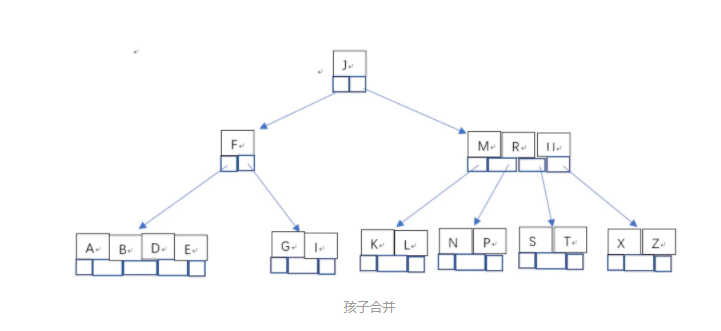
- 这样又出现只含有一个关键字F结点的情况,这时,发现其相邻的兄弟结点是丰满的(关键字个数为3>最小关键字个数2),这样就可以想父结点借关键字,把父结点中的J下移到该结点中,相应的如果结点中J后有元素则前移,然后相邻兄弟结点中的第一个关键字(或者最后一个关键字)上移到父节点中,后面的关键字(或者前面的关键字)前移(或者后移);注意含有K,L的结点以前依附在M的左边,现在变为依附在J的右边。这样每个结点都满足B树结构性质。
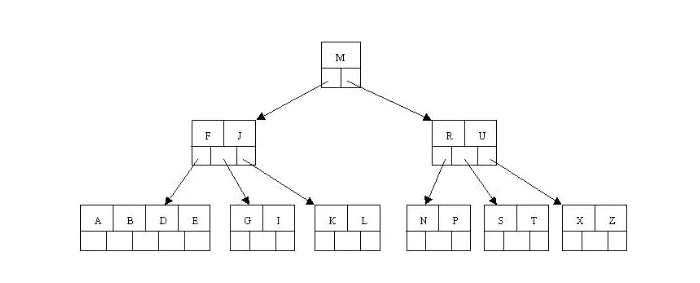
一颗m阶的B 树和m阶的B树的差异在于:
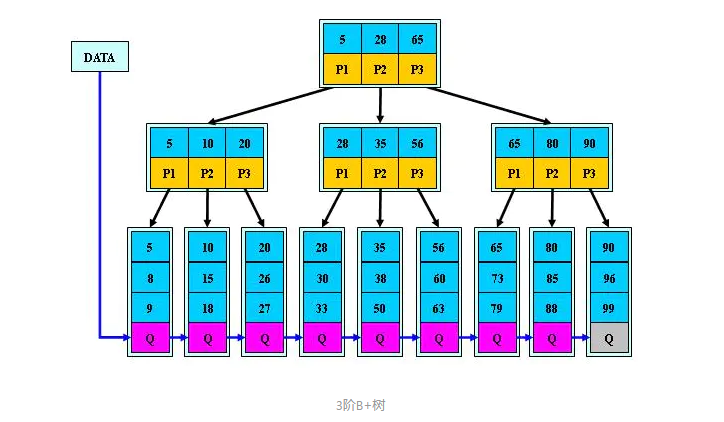
1.非叶子结点的子树指针与关键字个数相同;
2.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i 1])的子树(B-树是开区间)
3.为所有叶子结点增加一个链指针。图中Q是通过指针连在一起的。
4.所有关键字都在叶子结点出现。(5 8 9 10 15 18 20 26 …等等)叶子结点相当于是存储(关键字)数据的数据层;
5.B 树只有达到叶子结点才命中(B-树可以在非叶子结点命中)
6.所有的非终端结点可以看成是索引部分,结点中的关键字是有其孩子指向的子树中最大(或最小)关键字。比如第二层5 它的子树为5 8 9 (而B 树的非终节点也包含需要查找的有效信息)
B 树在MyISAM索引实现
叶节点的data域存放的是数据记录的地址
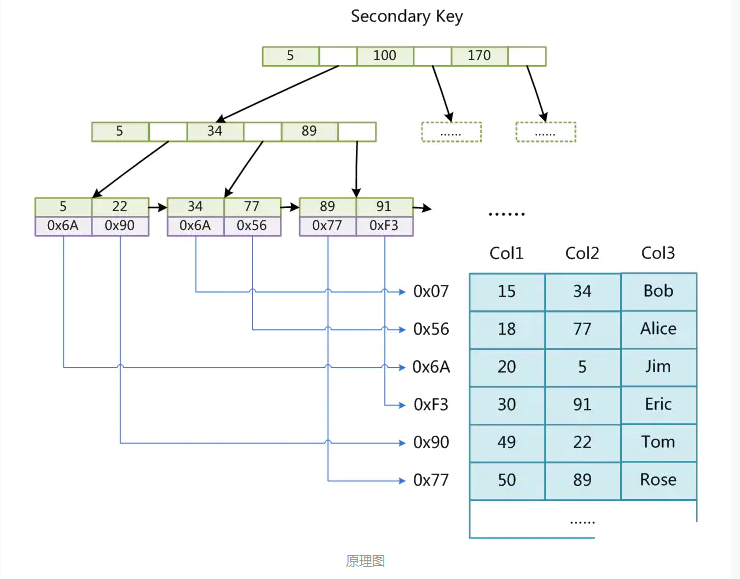
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
B 树在InnoDB索引实现
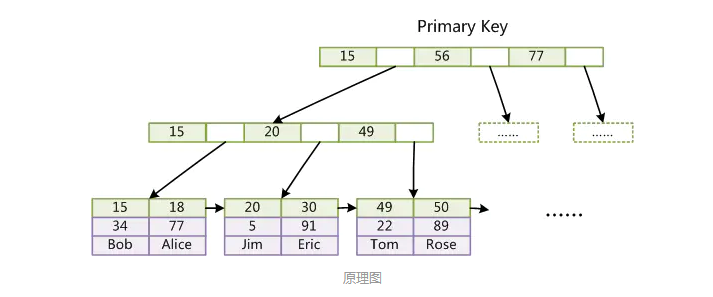
- 第一个重大区别是InnoDB的数据文件本身就是索引文件。
从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
而在InnoDB中,表数据文件本身就是按B Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。 - 从示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
- 第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如
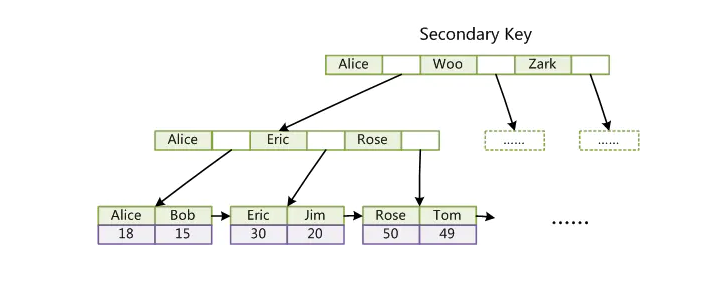
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
所以应该注意的地方
- 为什么不建议使用过长的字段作为主键?
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。 - 在InnoDB中不要用非单调的字段作为主键。
因为InnoDB数据文件本身是一颗B Tree,非单调的主键会造成在插入新记录时数据文件为了维持B Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
B树JAVA代码实现例子
七、为什么说B 树比B树更适合数据库索引?
1、 B 树的磁盘读写代价更低:B 树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B 树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B 树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B 树更加适合在区间查询的情况,所以通常B 树用于数据库索引。
文章参考:
http://lday.me/2018/02/21/0020_b_tree_summary/
https://blog.csdn.net/endlu/article/details/51720299
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
作者:爱笨笨的阿狸
链接:https://www.jianshu.com/p/ac12d2c83708
来源:简书