
搭建日志收集分析平台-Filebeat+ELK/logServer
虽然一直在用各种的日志平台,但是一直没搞一个一个属于自己的日志记录分析平台,平时都是搞一个db或者直接存到crontab里面,机器多了就太分散了。前面说到了有机器了 那就搞一个吧,毕竟算力不等于生产力,要把算力转换成生产力才可以啊。
日志平台现在大多都是基于elasticsearch的。这个没什么好选型的。完全够用也好用。这次搭建的整体就是基于elk的。日志收集分类两个途径一种是基于filebeat收集,另外一种是编写一个logApi通过http收集定制统一个日志格式。先上一个简单的架构图吧
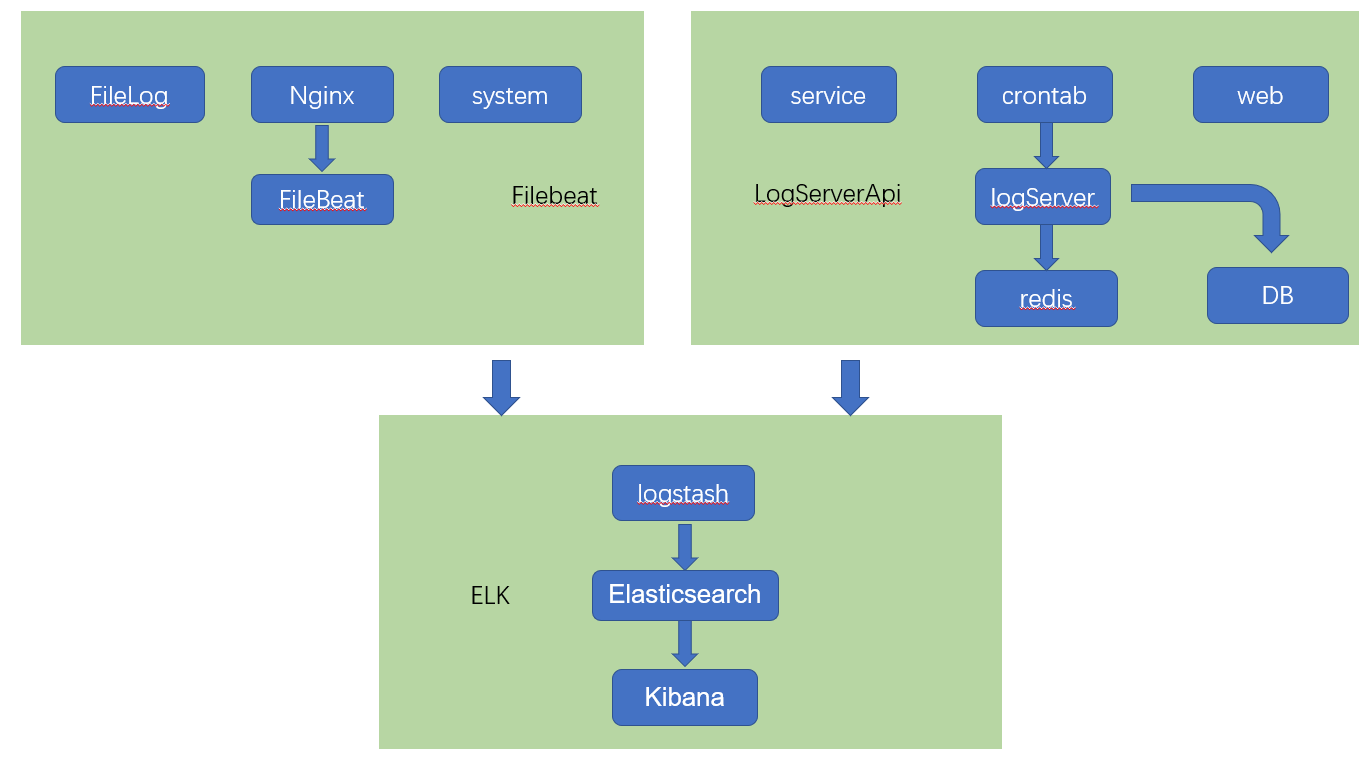
其中elk是docker中安装,filebeat安装在日志收集的机器上主要用来收集nginx和系统的各种日志,其实可以nginx可以通过udp上报日志,有兴趣的可以了解下。
logServer主要是为了提供一个统一的http的接口,用来上报日志,这样在各个业务或者脚本中直接上报。
这里安装的过程就不详细展开了,网上攻略很多,但是还是那句话,“纸上得来终觉浅,须知此事要躬行”。这篇吧整个安装开发的过程中遇到的要点步骤或者自己的成长点mark一下。
第一:安装ELK
主要参考:https://elk-docker.readthedocs.io/#installation
这里采用的 sebp/elk 官方镜像compose安装方式。
elk:
image: sebp/elk
restart: always
ports:
- "5601:5601"
- "9200:9200"
- "5044:5044"
volumes:
- '/data/docker/elk/elasticsearch:/var/lib/elasticsearch'
我这里只把数据卷映射了,其他的没映射。
有一个点要注意logstash的ssl,默认是开启的,要把对应crt文件拷贝到宿主机,这个稍后filebeat上报logstash要用到。
docker中文件地址: /etc/pki/tls/certs/logstash-beats.crt (docker cp docker:file file)
安装好以后通过ip:port就可以访问到对应的服务了,但是毕竟不能每次都要输入ip
第二:配置Nginx的ServerName+配置Nginx 登录auth模块
logstash在新的版本了里面权限角色模块收费了,因为就个别人用所以不用那么复杂的角色,只要简单的登录认证就可以了这里采用nginx的 auth_basic
参考:http://www.appblog.cn/2019/07/09/Kibana%E7%99%BB%E5%BD%95%E8%AE%A4%E8%AF%81%E8%AE%BE%E7%BD%AE/
安装Apache密码生产工具
dnf install -y httpd-tools
生成密码文件
# mkdir -p /etc/nginx/passwd # htpasswd -c -b /etc/nginx/passwd/kibana.passwd user ******
Nginx-host (删除了配置信息,保留参考)
server
{
listen 80;
#listen [::]:80;
server_name server ;
#告诉浏览器有效期内只准用 https 访问
add_header Strict-Transport-Security max-age=15768000;
#永久重定向到 https 站点
return 301 https://$server_name$request_uri;
access_log /server.log;
}
server
{
listen 443 ssl http2;
#listen [::]:443 ssl http2;
server_name server ;
auth_basic "Kibana Auth";
auth_basic_user_file /etc/nginx/passwd/kibana.passwd;
location / {
proxy_pass_header Server;
proxy_pass http://localhost:5601;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
}
access_log /server.log;
}
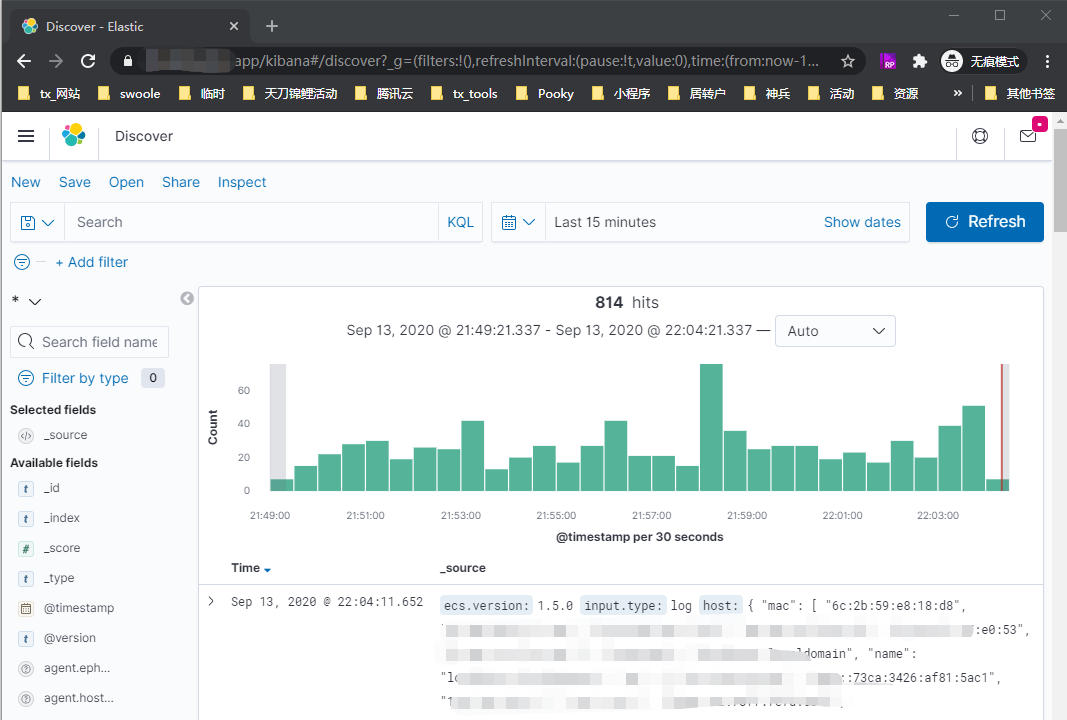
第三:安装Filebeat并开启nginx模块上报到logstash
这里采用的是yum安装直接安装就可以了,本来想在docker里面安装,后来一想我这不对啊,filebeat要收集文件日志,docker怎么能访问到宿主机里面的文件呢,太不方便了。filebeat还是应该安装到日志对应的机器上,不建议安装到docker里面,不能为了用而用还是应该考虑实际情况。
dnf install filebeat
开启nginx模块
filebeat modules list #显示所有的modules filebeat modules enable nginx # 开启某一个module filebeat modules disable nginx #关闭module
编辑对应的/etc/filebeat/filebeat.yml;/etc/filebeat/modules.d/nginx.yml这个就不细说了,要注意的一点是如果要上报到logstash,对应的crt文件要设置对。(要下载到宿主机哦)
开启log ,配置logstash(elasticsearch和logstash只能开启一个)
- module: nginx
access:
enabled: true
var.paths: ["/data/*.log"]
error:
enabled: true
var.paths: ["/data/nginx_error.log"]
# Ingress-nginx controller logs. This is disabled by default. It could be used in Kubernetes environments to parse ingress-nginx logs
ingress_controller:
enabled: false
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-beats.crt"]
其他的应该难度不大
这里关于自定义字段的耗费了我好多时间,在module里面定义的fileds无效,真的是服了。因为要根据传入的参数去生成不同的es 索引。最后传入是可以传入了但是可能我当时脑壳昏了,反正总觉得重启filebeat和lostash配置有延迟,这里要注意。最后决定用”event.module”这个系统自己传入的来做索引,这里在最后logstash部分说。
启动filebeat
[root@localhost filebeat]# systemctl start filebeat #启动
[root@localhost filebeat]# systemctl status filebeat #查看状态
* filebeat.service - Filebeat sends log files to Logstash or directly to Elasticsearch.
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2020-09-13 10:49:32 CST; 11h ago
Docs: https://www.elastic.co/products/beats/filebeat
Main PID: 1987911 (filebeat)
Tasks: 22 (limit: 202365)
Memory: 87.5M
[root@localhost filebeat]# systemctl stop filebeat #停止
[root@localhost filebeat]# systemctl restart filebeat #重启
当时搞fileds的时候有一段时间stop 特别慢,可能我nginx模块配置乱了,这里要注意,脑子不清醒的时候就暂时afk一会,不能钻牛角,效率不高
对了这里有一个filebeat集成了很多module的dashboard 这个自行百度一下吧 ,稍后我玩数据的时候也会小结一个再分享。
这个时候应该es应该已经有数据了,可以去看看了。
第四:开发一个logServer上报Api
这一步是我个人需要的,毕竟自己才知道自己需要的是什么。简单说一下思路 这里主要是logstash读取redis数据。
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-redis.html
redis的类型必须是”list”, “channel”, “pattern_channel其中一种,用队列或者订阅模式。这里我采用list因为订阅不会保留历史数据,无法保证日志是不是被消耗了。
还有一点比较好redis存的是json格式的logstash会自动格式化
例如:
127.0.0.1:6379> RPUSH logstash-list '{"key":"value","key1":"value1","key2":"value2","key3":"value3","key4":"hello张三"}'
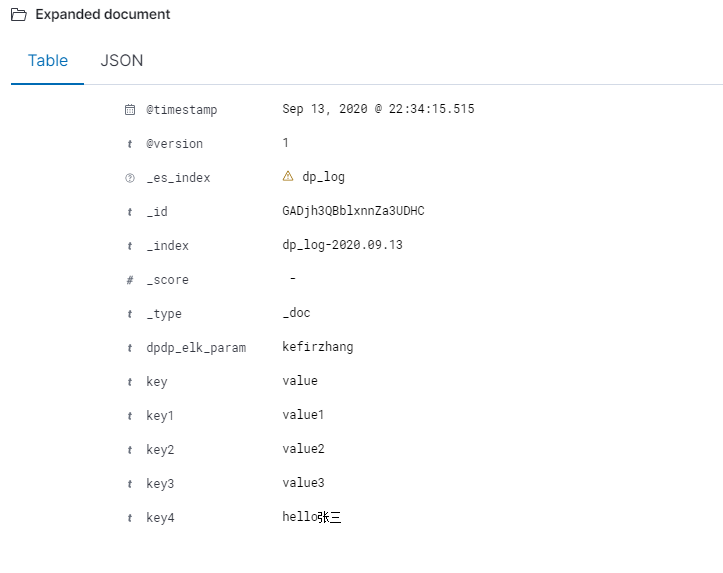
这样就可以按照自己的想法定义自己想要的字段 。程序的核心就是开启一个httpserver 收集上报的日志 存储到redis的list中。logstash会实时pop对应的数据到es。
这里保留了一份到数据库,留个后手吧。个人可以按照自己的喜好进行开发,安全验证 频率限制什么的有必要的话 不要忘了。
第五:logstash上报配置
所有的数据都是通过logstash上报到,其实很多可以直接上报到es,但是logstash还是很有必要的的,数据过滤清洗什么的。这里就不展开了,分享一下暂时的logstash的配置文件
/etc/logstash/conf.d/30-output.conf
filter {
mutate { add_field => { "[xxxx_elk_param]" => "diy_param" } }
}
output {
if [_es_index] == "xx_log" {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "%{[_es_index]}-%{+YYYY.MM.dd}"
}
} else if [event][module] in ["nginx", "system", "sys", "redis"] {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "%{[@metadata][beat]}-%{[event][module]}-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "default-%{+YYYY.MM.dd}"
}
}
}
通过不动字段传到不同的index索引里面。
第六:最后展示一下最后页面
第一:logServer上报。这里模拟postman发送一个log
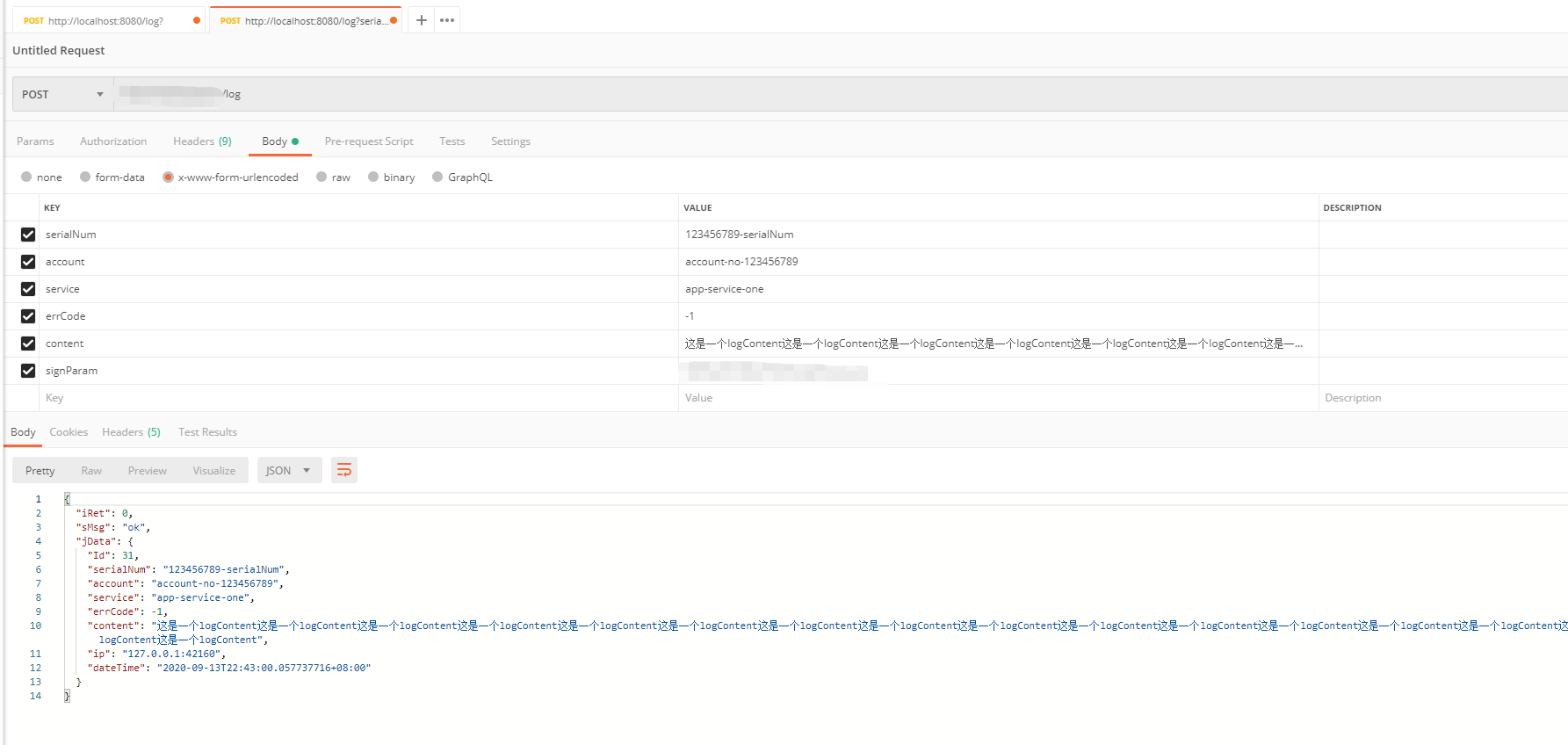
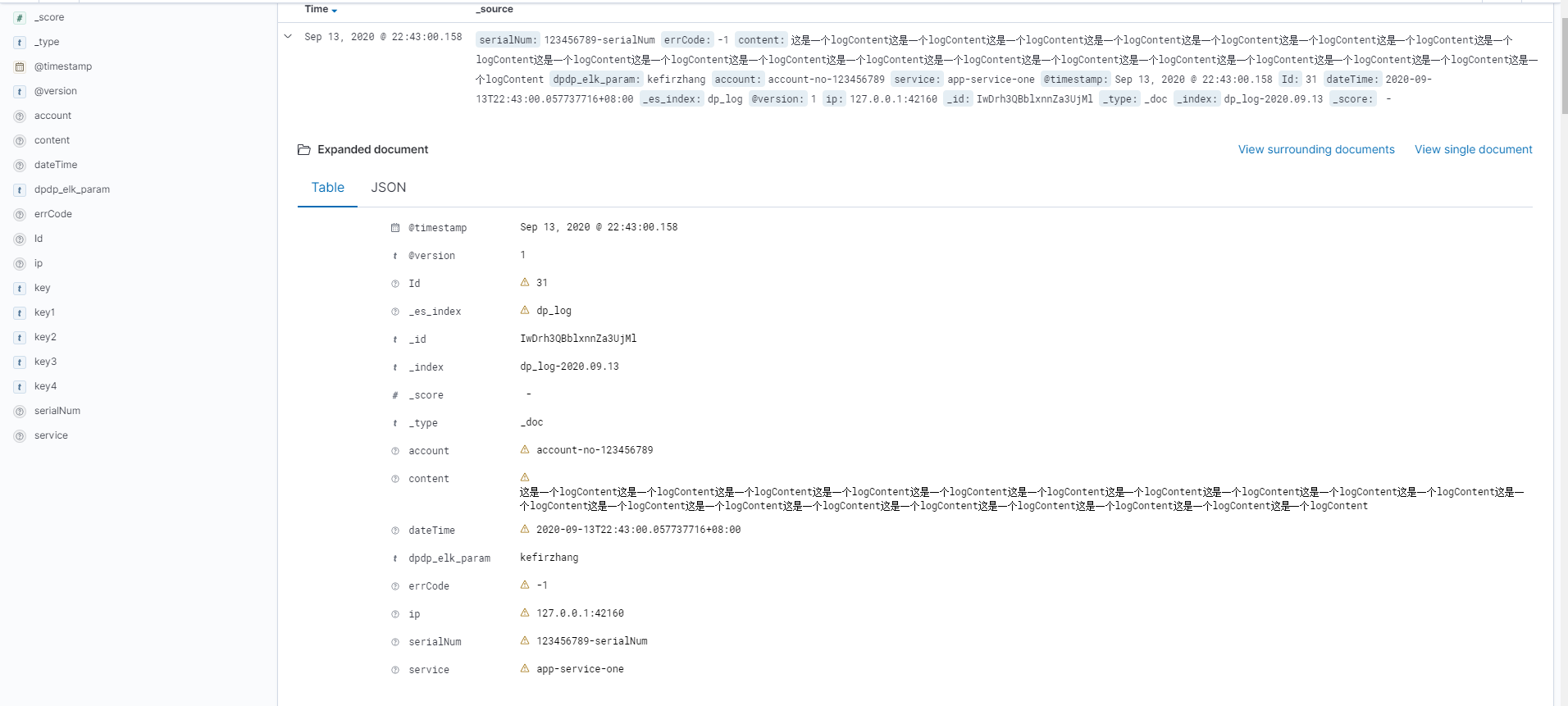
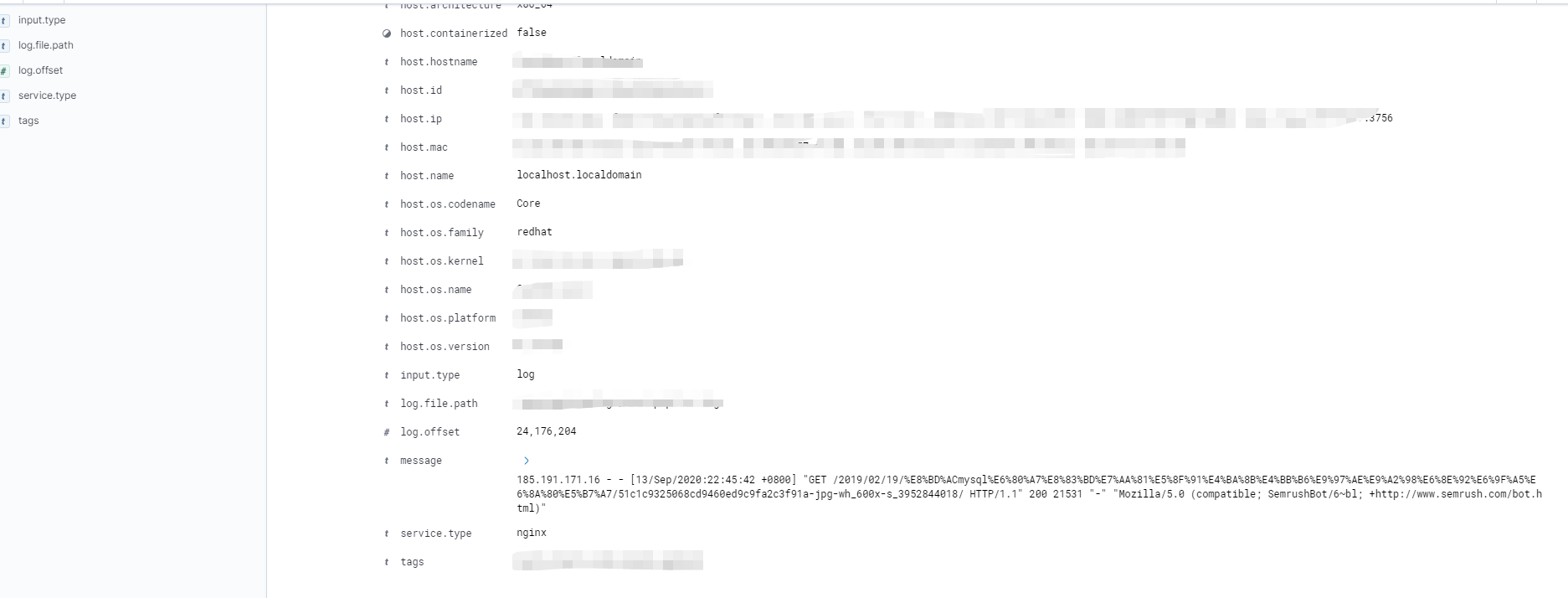
第二:nginx日志:
这里nginx-format可以参考官方的log-format 自定义自己想要的数据,filebeat自带的module格式化不太好,所有的数据都存在message里面,如果有线上产品生产环境 那么就要优化了 吧对应的字段拆分开开 做聚合分析,可以nginx单独上报不用filebeat的模式
小结:这几个东西搞了好几天,单个还好,整体的配合要顺利的整合到一起还是需要反复的调试的。不过还是很值得的,以前每次都是做点东西太零散而且不成体系,做过没用还是没什么积累。构建了东西就要用。要自己使用不断的磨合才能发现问题。算力不等于生产力,优化提高生产力。日志分析平台了有了 那么监控告警就可以提上日程了


