
聊聊跳表原理及为什么Redis要使用跳表来实现zset
题外话:发现自己写的博客不善于吧细节调理写的很明白,更多时候连小结都不愿意写,这个行为不好,要改。
今天来说说“跳表”,其实跳表一般在各种算法与数据结构的教程中都没有出现,或者也不会深入讲解。我以前也是在各种文章中看过这个概念,但是一直没有去深入了解,最近因为各种原因需要做个分享,这个是个不错的课题。就研究了下。这里整理下自己的理解,如果有不小心看到这篇的 需要全面了解的可以参考
其实现在很多文章网上都有各个同学进行了详细的分析整理,学到了很多,这里小结下自己的一些理解 (个人理解不一定严谨)
首先我们程序 就是 算法 + 数据。而数据 其中 比较重要的是 存储(增删改) 和 检索
我们大部分时间优化的项目都是面围绕存储和检索的时间复杂度和空间复杂度。检索的数据结构现在常见的有哈希、有序数组、搜索树(各种树)当然还有我们今天要说的跳表。我这里整理了一个简单的表格用来做个对比
| 数据结构 | 实现原理 | key查询方式 | 查找效率 | 存储大小 | 变更效率 |
| Hash | 哈希表 | 单Key | O(1) | 小,除了数据没有额外的存储 | O(1) |
| 有序数组 | 有序数组 | 单Key,范围 | O(Log(n) | 小紧凑 | O(n) |
| B+树 | 平衡二叉树扩展而来 | 单Key,范围 | O(Log(n) | 除了数据,还多了左右指针,以及叶子节点指针 | O(Log(n),需要调整树的结构,算法比较复杂 |
| 跳表 | 有序链表扩展而来 | 单Key,范围 | O(Log(n) | 除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小 | O(Log(n),只用处理链表,算法比较简单 |
这里就不过多解释了,还是那个宗旨 目前博客只记录个人理解。
优化数据检索 那么两个方向 第一个存储的时候按照一定规则来存储,第二个用多余的空间来建立索引。这两个基本都是同时出现的。
建立索引是检索的最常见也是个人理解下来最有效的方法。不管常见索引还是倒排索引。核心就是用多余的空间来换取效率
而跳表就是在有序链表的基础上发展而来,那么也要解决两个问题:如何优化数据存储和数据检索
第一如何优化数据存储:
我们按照B+树来做对比,存储就是一个平衡搜索树,如果要插入一个节点那么就检索到这个节点插入,插入的时候要维护子树的规则(平衡搜索树)还有就是B+树在mysql当中还要在一定的情况下扩容和缩容。这就要消耗一定的资源算力,而跳表这里用随机层数来解决这个问题,我觉的只是神来之笔
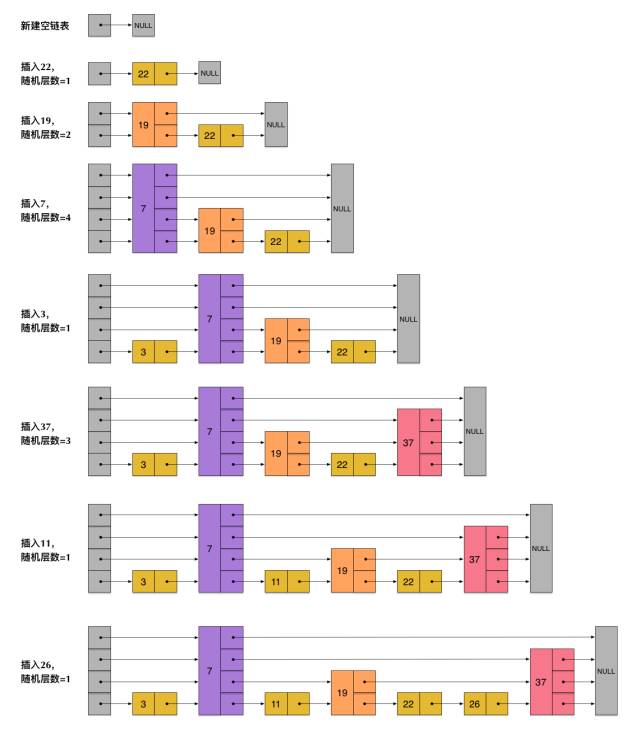
这样就解决了插入的消耗问题,比平衡术更加优秀。
第二点:检索效率
这里其实能够达到log(N)已经基本达到常规分治检索算法的极致了!就不过多说了!这里还是上一个图 基本一看就明白就是分治的算法思想

分治思想检索的一般都是对数级别的效率,这里就不展开了。
解决了这两个问题这个跳表完全可以替代平衡搜索树来来用。其实个人理解跳表跟树在思想上也有共同之处。只是相同道之下的不同术。
至于为什么Redis不用平衡搜索树来做,结合Redis作者的话和我自己的理解,首先我认为这么做挺好的,确实在保证底线(最差)的情况下在某些时候还有亮点。
1)内存占用更少,自定义参数化决定使用多少内存
2)有序集合很多时候用zrange 或者zrevrange 。性能至少不比平衡树差
3)简单更容易实现和维护
这个跳表其实小结下来不是什么新鲜东西,但是有很多值得学习和借鉴的地方。
一句话总结什么是跳表:跳表就是在有序链表的基础上通过增加额外的指针节点来解决查询效率,通过随机插入来提高变更效率的一种数据结构。
一句话总结为什么Redis要用跳表来实现zset:内存使用更少,简单易维护,性能不比搜索树差


