
Protocol Buffer 案例实践和原理学习
背景:
作为一个PHP为主的后台开发,怎么会想到来研究Protocol Buffer呢?一切还得从那一天开始说起。那是一个特别的日子……
其实这样说吧
第一:想要把开发和部署环境上到公司的CI/CD平台
第二:需要学习使用公司的微服务框架
第三:公司的微服务框架的RPC模块是基于gRPC实现的
第四:需要研究下gRPC的核心模块: 通用数据结构和网络传输
第五:gRPC的序列化编码是Protocol Buffers
所以就像函数的执行一样 现在的问题就是研究下这个Protocol Buffers 是个什么东东
简介:
官方介绍:
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the “old” format.
个人理解:
Protocol buffers 首先核心是用来序列化或者说结构化数据结构的,就像XML ,JSON
轻便高效的结构化数据存储格式,很适合用来做数据存储或者做RPC的数据交换格式,业界不是最快的 但是肯定比xml和json快(有种成人专找小学生pk的感觉)
核心小结:
谷歌开源的一种与语言无关,与平台无关的用来结构化或者序列化通用数据结构的协议规范(更快/更高/更强,至于为啥下面会简单唠几句)
HelloWorld示例
安装环境
这边环境是mac所以直接brew 就可以了
brew install protobuf
除此之外还需要安装对应语言的编译工具
各个语言的详见:
https://github.com/golang/protobuf
这里使用go做本次示例 需要安装protoc-gen-go
https://github.com/golang/protobuf
go get -u github.com/golang/protobuf/protoc-gen-go
关于例子:
引用官方例子: 各个语言版本-》https://github.com/protocolbuffers/protobuf/tree/master/examples
做一个通讯簿,主要两个功能新增联系人,查看联系人列表
首先定义proto文件
syntax = "proto3";
package pb;
import "google/protobuf/timestamp.proto";
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
option csharp_namespace = "Google.Protobuf.Examples.AddressBook";
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}
message AddressBook {
repeated Person people = 1;
}
这里用到的示例信息比较多,简单说一下内容
定义了语法版本,如果不定义默认是proto2
定义了Person结构体 包含name id email PhonNumber PhonType各个类型,对应的具体字段含义可以参考https://developers.google.com/protocol-buffers/docs/proto3
option这些选项可以看到是兼容不同语言来配置的,在go可以不配置
下一步:通过编译器生成对应语言的数据格式接口文件
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR --go_out=DST_DIR --ruby_out=DST_DIR --objc_out=DST_DIR --csharp_out=DST_DIR path/to/file.proto //实际 protoc -I . addressbook.proto --go_out=.
不同的语言生成不同的接口文件go 生成后缀为*.bp.go的文件
里面会定义好相应的数据结构体和绑定序列化函数
type Person_PhoneNumber struct {
Number string `protobuf:"bytes,1,opt,name=number,proto3" json:"number,omitempty"`
Type Person_PhoneType `protobuf:"varint,2,opt,name=type,proto3,enum=pb.Person_PhoneType" json:"type,omitempty"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_unrecognized []byte `json:"-"`
XXX_sizecache int32 `json:"-"`
}
func (m *Person_PhoneNumber) Reset() { *m = Person_PhoneNumber{} }
func (m *Person_PhoneNumber) String() string { return proto.CompactTextString(m) }
func (*Person_PhoneNumber) ProtoMessage() {}
func (*Person_PhoneNumber) Descriptor() ([]byte, []int) {
return fileDescriptor_1eb1a68c9dd6d429, []int{0, 0}
}
func (m *Person_PhoneNumber) XXX_Unmarshal(b []byte) error {
return xxx_messageInfo_Person_PhoneNumber.Unmarshal(m, b)
}
func (m *Person_PhoneNumber) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
return xxx_messageInfo_Person_PhoneNumber.Marshal(b, m, deterministic)
}
func (m *Person_PhoneNumber) XXX_Merge(src proto.Message) {
xxx_messageInfo_Person_PhoneNumber.Merge(m, src)
}
func (m *Person_PhoneNumber) XXX_Size() int {
return xxx_messageInfo_Person_PhoneNumber.Size(m)
}
func (m *Person_PhoneNumber) XXX_DiscardUnknown() {
xxx_messageInfo_Person_PhoneNumber.DiscardUnknown(m)
}
var xxx_messageInfo_Person_PhoneNumber proto.InternalMessageInfo
func (m *Person_PhoneNumber) GetNumber() string {
if m != nil {
return m.Number
}
return ""
}
func (m *Person_PhoneNumber) GetType() Person_PhoneType {
if m != nil {
return m.Type
}
return Person_MOBILE
}
add_pserson.go
里面核心
.....
func promptForAddress(r io.Reader) (*pb.Person, error) {
// A protocol buffer can be created like any struct.
p := &pb.Person{}
rd := bufio.NewReader(r)
fmt.Print("Enter person ID number: ")
// An int32 field in the .proto file is represented as an int32 field
// in the generated Go struct.
if _, err := fmt.Fscanf(rd, "%d\n", &p.Id); err != nil {
return p, err
}
//.......... 各种参数
return p, nil
}
func main() {
.....
book := &pb.AddressBook{}
if err := proto.Unmarshal(in, book); err != nil {
log.Fatalln("Failed to parse address book:", err)
}
// Add an address.
addr, err := promptForAddress(os.Stdin)
if err != nil {
log.Fatalln("Error with address:", err)
}
book.People = append(book.People, addr)
// [END_EXCLUDE]
// Write the new address book back to disk.
out, err := proto.Marshal(book)
if err != nil {
log.Fatalln("Failed to encode address book:", err)
}
if err := ioutil.WriteFile(fname, out, 0644); err != nil {
log.Fatalln("Failed to write address book:", err)
}
// [END marshal_proto]
}
list_people.go
func writePerson(w io.Writer, p *pb.Person) {
fmt.Fprintln(w, "Person ID:", p.Id)
fmt.Fprintln(w, " Name:", p.Name)
if p.Email != "" {
fmt.Fprintln(w, " E-mail address:", p.Email)
}
for _, pn := range p.Phones {
switch pn.Type {
case pb.Person_MOBILE:
fmt.Fprint(w, " Mobile phone #: ")
case pb.Person_HOME:
fmt.Fprint(w, " Home phone #: ")
case pb.Person_WORK:
fmt.Fprint(w, " Work phone #: ")
}
fmt.Fprintln(w, pn.Number)
}
}
func listPeople(w io.Writer, book *pb.AddressBook) {
for _, p := range book.People {
writePerson(w, p)
}
}
func main() {
if len(os.Args) != 2 {
log.Fatalf("Usage: %s ADDRESS_BOOK_FILE\n", os.Args[0])
}
fname := os.Args[1]
in, err := ioutil.ReadFile(fname)
if err != nil {
log.Fatalln("Error reading file:", err)
}
book := &pb.AddressBook{}
if err := proto.Unmarshal(in, book); err != nil {
log.Fatalln("Failed to parse address book:", err)
}
listPeople(os.Stdout, book)
}
运行示例:
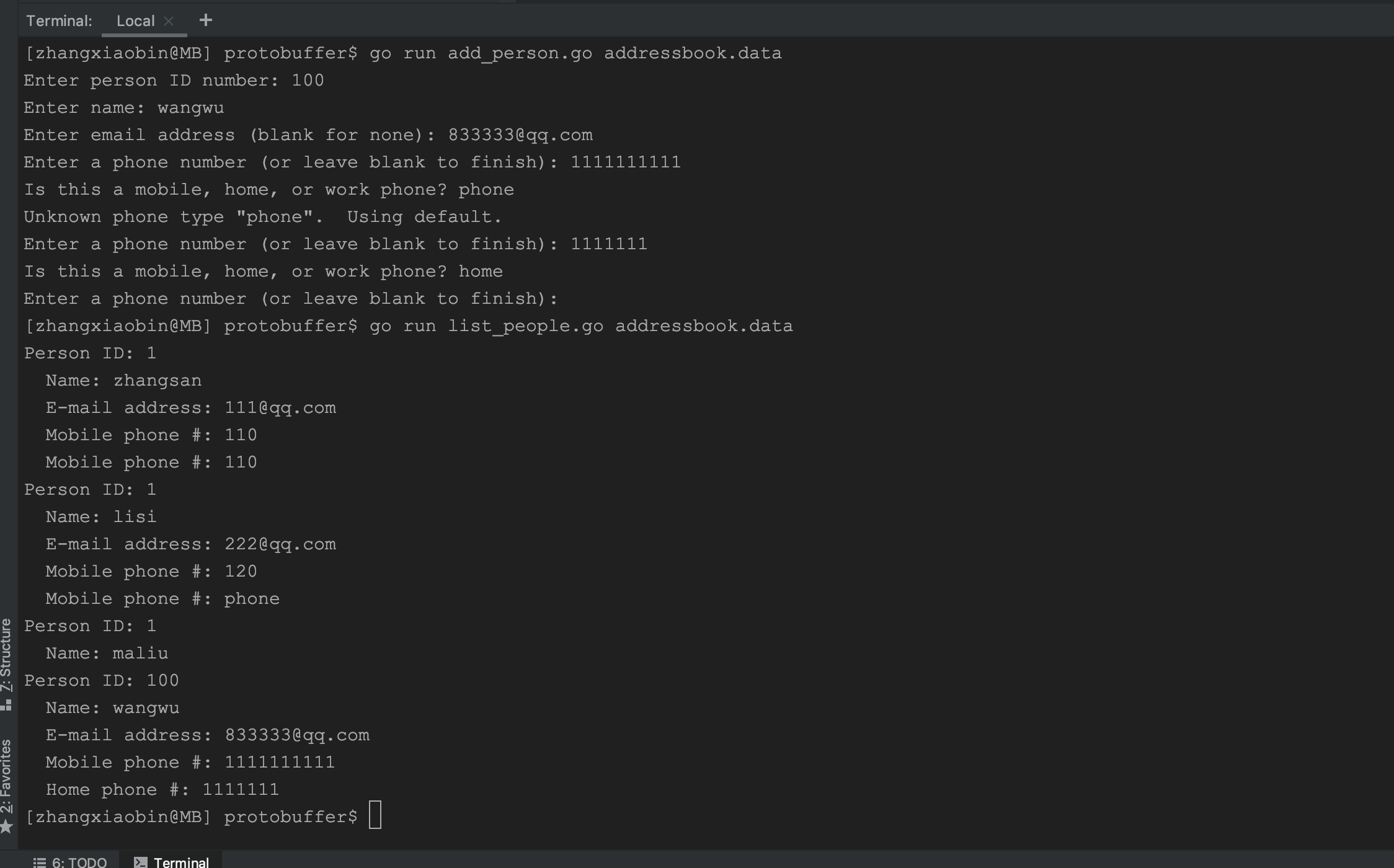
上面的例子简单了介绍下protocol buffer的使用,在rpc框架中主要是底层把文件存储改成了网络传输。关于网络传输这边也是有很多可以研究的这里就不展开了。
到这里你会问这东西json 和xml 都能做啊 为什么非的用你呢,下面我们来说下他快的原理
原理学习
谷歌一直强调相比于Json和XMl等文本协议,Protobuf的主要优点在于性能高,它是以二进制进行存储和传输的,比xml小大概10倍快20倍以上。
这里的体积小和速度快要分两个部分来说,
第一部分:体积小,protobuf序列化后信息表非常紧凑,意味着消息体积减少,自然需要更少的资源更少的字节,减少IO操作
第二部分:速度快,主要是序列化和反序列化的过程,对比xml的过程就会理解为什么比xml快。
体积小
官方文档
https://developers.google.com/protocol-buffers/docs/encoding
他提出protobuf采用了“base 128 varints”编码规范,这是一种变字节长度的编码规范。举个例子 在数据库中 int bigint double占用的空间是固定的,而varchar占用的空间是不固定的。放到程序里面有些类型int是长度固定的而string的长度是不固定的,在传输后解析的的时候需要有专门的数据用来存储内容是什么数据类型的,对应的数据流长度是多少。
type data +--------+--------+~~+--------+ |xxxxxxxx|xxxxxxxx| |xxxxxxxx| +--------+--------+~~+--------+ 7 0 7 0 7 0 type=string length data +--------+--------+~~+--------+ |xxxxxxxx|xxxxxxxx| |xxxxxxxx| +--------+--------+~~+--------+ 7 0 7 0 7 0
那么如果我们制定一个数据编码规范,数据类型是有限的 1个字节基本够用,但是length 用多少个字节来表示呢1个字节最大是255,如果用一个字节那么字符串长度不成超过255 那么肯定是不行的,使用两个字节65535,如果更长呢,因为长度是变化的,所以用固定的来表示不是很友好,如果太短那么范围太小,如果太长那么传输太浪费。如果我们用4字节来表示1 那么 就是length 对应的 00000000 00000000 00000000 00000001 太浪费了。那么问题来了,如何去掉这些零呢?
不同的协议有不同的优化方法,
websocket采用的方式 首先用7bit的长度来表示length,当长度值达到126的时候接着再传输两个字节表示真正的长度,以此类推,当达到下一个标识位的时候 再传输8个字节来表示真正的长度。(可能不够详细,简单按照自己的理解来说)
websoket 协议中征用了 126 和 127 这两个数字表示长度字段总共占几个字节,以达到动态扩展的效果。VarInts 则是征用了每个字节的最高位(MSB)。具体表示方式如下表:
0 ~ 2^07 - 1 0xxxxxxx 2^07 ~ 2^14 - 1 1xxxxxxx 0xxxxxxx 2^14 ~ 2^21 - 1 1xxxxxxx 1xxxxxxx 0xxxxxxx 2^21 ~ 2^28 - 1 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx 2^28 ~ 2^35 - 1 1xxxxxxx 1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx
也就是说 length的字节是直到首位不是1的字节为止。
https://en.wikipedia.org/wiki/LEB128
MSB ------------------ LSB
10011000011101100101 In raw binary
010011000011101100101 Padded to a multiple of 7 bits
0100110 0001110 1100101 Split into 7-bit groups
00100110 10001110 11100101 Add high 1 bits on all but last (most significant) group to form bytes
0x26 0x8E 0xE5 In hexadecimal
→ 0xE5 0x8E 0x26 Output stream (LSB to MSB)
这里解决了数据变长的问题。还有一个问题,数据映射问题
按照官方例子定义一个消息类型:我们搭建一个grpc简单的server和client 来传输一个a=300
//protoc -I . hi.proto --go_out=plugins=grpc:.
//https://developers.google.com/protocol-buffers/docs/proto3
syntax = "proto3"; // 指定 proto 版本
package btest; // 指定包名
// 定义 Hi 服务
service Hi {
rpc SayHi(HiRequest) returns (HiResponse) {}
}
// HiRequest 请求结构
message HiRequest {
int32 a = 1;
}
// HiResponse 响应结构
message HiResponse {
int32 a = 1;
}
我们启用wireshark来抓包
我们确认300对应的二进制是什么 方便查看反推
1010 1100 0000 0010 去掉左边最高位 000 0010 010 1100 → 000 0010 ++ 010 1100 → 100101100 → 256 + 32 + 8 + 4 = 300
抓包
返回的结果为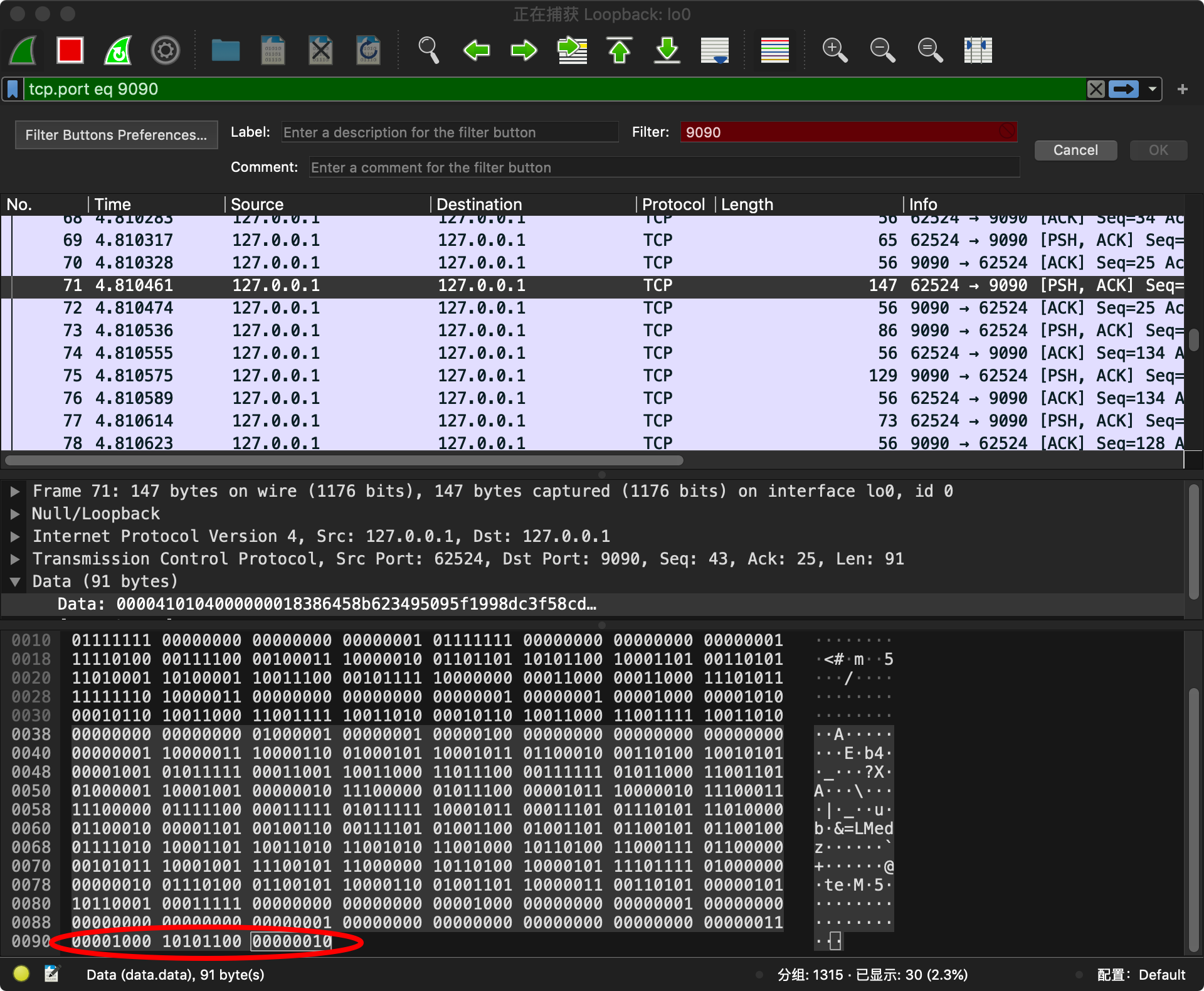
对应的是
08 ac 02
0000 1000 1010 1100 000 0010
三个字节表示了a 等于300
信息流如下图
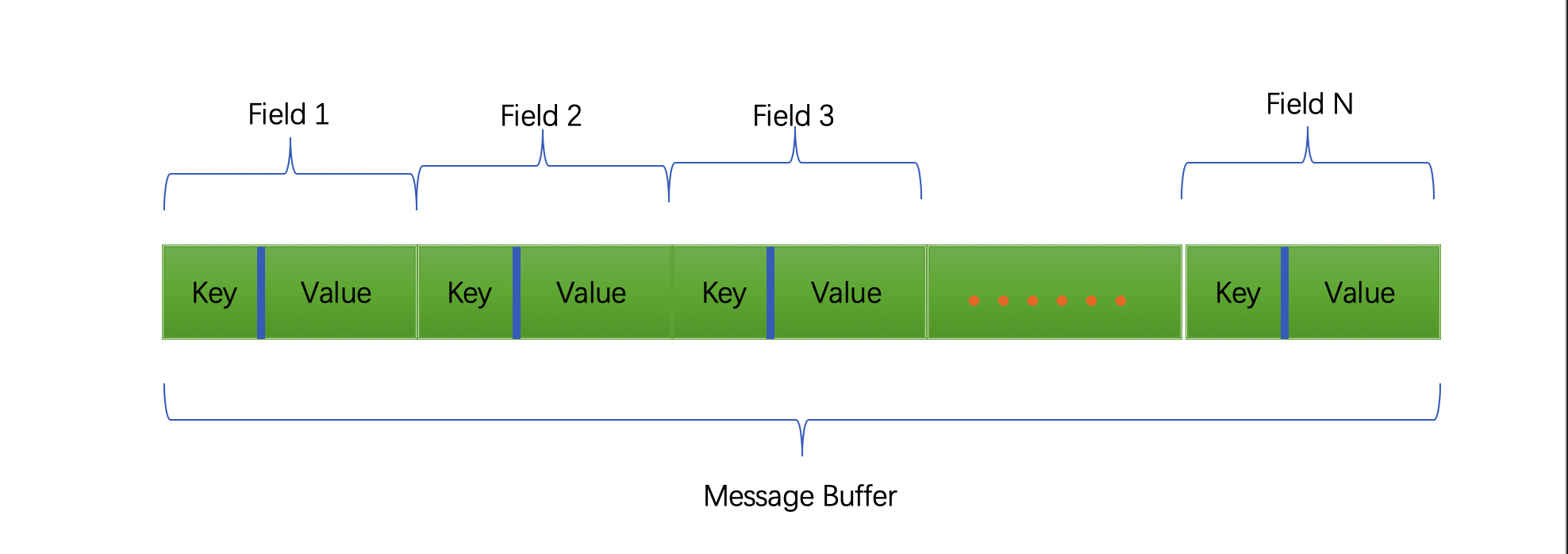
每一个Field由 key 和value 组成
其中key 由 (field_number << 3) | wire_type 组成
其中wire_type
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
就以上看的例子来说:int32 对应0 filed_number = 1 1 << 3 为 00001 000 后三位用来存储wire_type 这里是0 那么最终key为 0 0001 000
这里要注意也是所有说到proto3里面的 因为用到了varInts 那么首位要留出来 那么只有四位来表示filed_number 所以不要超过16 否则就要占用两个字节
下面来做个示例 多个字段
// HiRequest 请求结构
message HiRequest {
int32 a = 1;
int32 b = 16;
}
// HiResponse 响应结构
message HiResponse {
int32 a = 1;
int32 b = 16;
}
同样的传300 好做比较
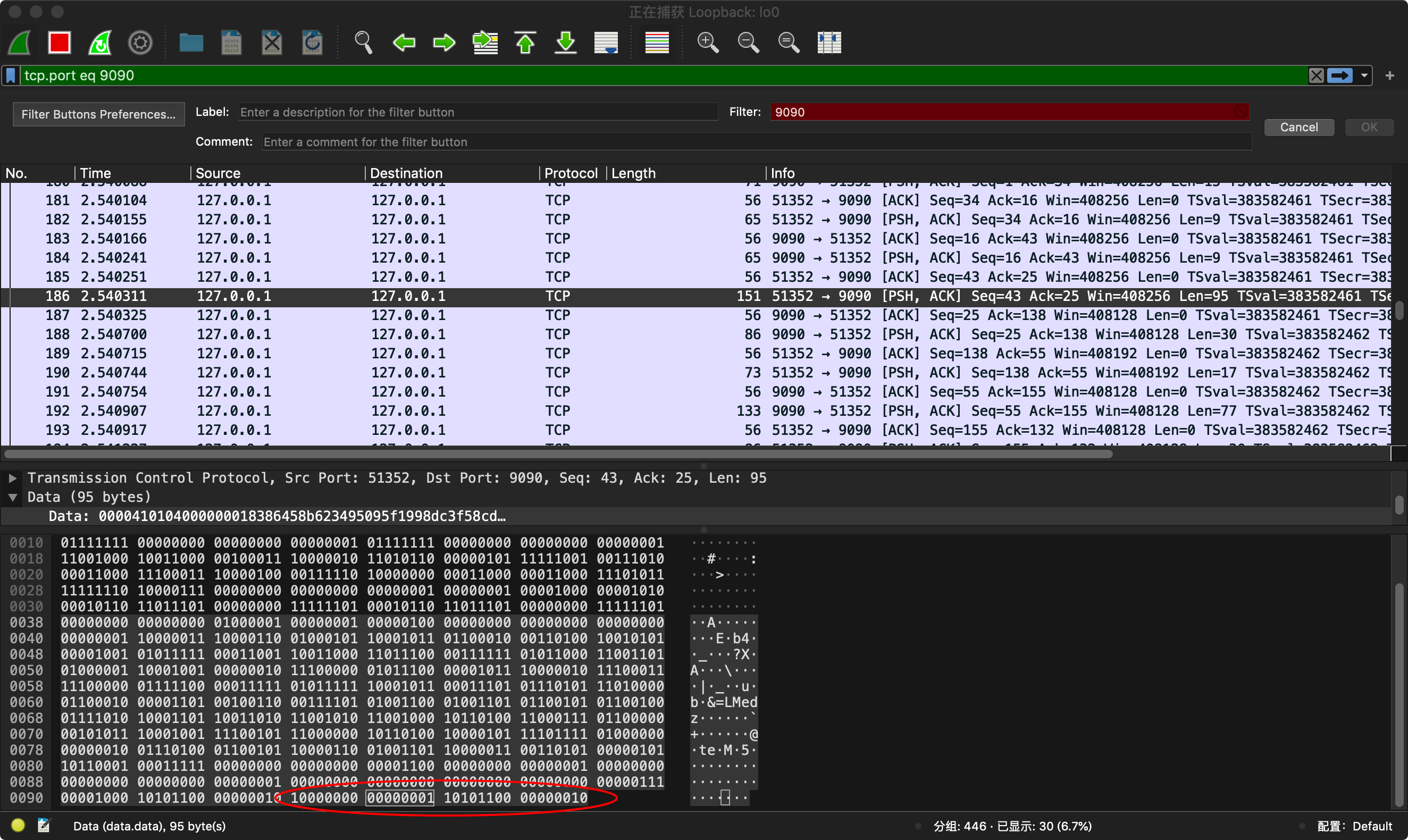
可以看到 key 用了两个字节,所以用protobuf 建议id 不要超过15(16及以上)
核心的原理就是这样,多种类型的以此类推 稍后我会给出一些参考博文,就不重复造轮子了。
还有就是protobuf 对负数进行了优化 增添了sint32这种类型 采用zigzag编码
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
运算方法
//32bit (n << 1) ^ (n >> 31) //64bit (n << 1) ^ (n >> 63)
而对于xml等文本则需要传输类似下面的 这边就不抓包了。肯定不止6个字节预计在60个以上
<HiRequest>
<a>300</a>
<b>300</b>
</HiRequest>
小结以下:其实protobuf 采用了varints 进行数据编码,让数据流更加紧凑。对负数采用zigzag编码。对于对字段采用利用varints特性紧凑的排列key->value,key->value,避免了标识位的使用从而让数据流大大减少。
速度快
这里的速度快其实是相对以常规的xml解析,这个xml详细的展开可以自行搜索。这边根据我的理解简单说下
首先读取字符串,转换成xml的文档对象类型。再从结构中逐一读取节点的属性和值,然后把这些信息转变成制定类型的变量。这个过程的需要消耗较大的cpu和复杂的计算。
反而protobuf 首先读取的是二进制,按照对应生成好的结构读取到对应的结构类型就可以了。而对应的decoding 根据上面说的coding过程进行位运算就可以了,速度非常快。
对速度快这一方面的深入实践和原理还不够深入,只是初步了解。更具体准备等有时间阅更深入的研究后单开一篇。但是大致的思想如上。
1:根据字段id的特性 尽量控制在1-15个(大多数文章说不要超过16个 容易给人误解 以为16也可以,但是16已经使用两个字节了)
2:虽然protobuf对于修改可以做到兼容,但是还是建议尽量在设计之初就完善设计,尽量少改动
3:如果使用负数可以使用sint32 sint64
4:可以为自己保留一些字段
题外话:
这里大概了解了微服务框架里面的一点,就像学习路线一样由面到点,由点连线,最后再铺成面。还有很多的东西知其然不知其所以然,应用开发做多了拿来主义成为了习惯。这篇只是微服务架构里面的rpc模块的一种实现框架grpc的里面的一个技术点,有没有一种函数执行入栈的感觉。本篇还是helloworld级别的。更多的是自己的理解,难免有理解偏颇的地方,还望各位大牛指正。
虽然学习中文档为主,但是还是参考了很多前人的分享 如果在描述中有些不是很全面可以参考下面资料
https://developers.google.com/protocol-buffers
https://developers.google.com/protocol-buffers/docs/gotutorial
https://developers.google.com/protocol-buffers/docs/encoding
https://en.wikipedia.org/wiki/LEB128
https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/index.html
https://zhuanlan.zhihu.com/p/73549334


